 Scrapy 框架介绍与安装
Scrapy 框架介绍与安装
# 1. Scrapy 框架介绍
Scrapy 是 Python 开发的一个快速,高层次的屏幕抓取和 web 抓取框架,用于抓取 web 站点并从页面中提取结构化的数据。Scrapy = Scrach+Python
Scrapy 用途广泛,可以用于数据挖掘、监测和自动化测试、信息处理和历史档案等大量应用范围内抽取结构化数据的应用程序框架,广泛用于工业
Scrapy 使用 Twisted 这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。Scrapy 是由 Twisted 写的一个受欢迎的 Python 事件驱动网络框架,它使用的是非堵塞的异步处理
# 1.1 为什么要使用 Scrapy?
- 它更容易构建和大规模的抓取项目
- 它内置的机制被称为选择器,用于从网站(网页)上提取数据
- 它异步处理请求,速度十分快
- 它可以使用自动调节机制自动调整爬行速度
- 确保开发人员可访问性
# 1.2 Scrapy 的特点
- Scrapy 是一个开源和免费使用的网络爬虫框架
- Scrapy 生成格式导出如:JSON,CSV 和 XML
- Scrapy 内置支持从源代码,使用 XPath 或 CSS 表达式的选择器来提取数据
- Scrapy 基于爬虫,允许以自动方式从网页中提取数据
# 1.3 Scrapy 的优点
- Scrapy 很容易扩展,快速和功能强大;
- 这是一个跨平台应用程序框架(在 Windows,Linux,Mac OS 和 BSD)。
- Scrapy 请求调度和异步处理;
- Scrapy 附带了一个名为 Scrapyd 的内置服务,它允许使用 JSON Web 服务上传项目和控制蜘蛛。
- 也能够刮削任何网站,即使该网站不具有原始数据访问 API;
# 1.4 整体架构大致如下:
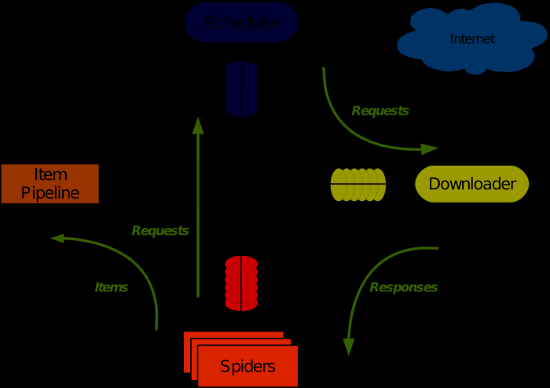
最简单的单个网页爬取流程是 spiders > scheduler > downloader > spiders > item pipeline
# 1.5 Scrapy 运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把 URL 封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析 Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把 URL 交给调度器等待抓取
# 1.6 Scrapy 主要包括了以下组件:
- 引擎(Scrapy)
- 用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler)
- 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个 URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader)
- 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy 下载器是建立在 twisted 这个高效的异步模型上的)
- 爬虫(Spiders)
- 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让 Scrapy 继续抓取下一个页面
- 项目管道(Pipeline)
- 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares)
- 位于 Scrapy 引擎和下载器之间的框架,主要是处理 Scrapy 引擎与下载器之间的请求及响应
- 爬虫中间件(Spider Middlewares)
- 介于 Scrapy 引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出
- 调度中间件(Scheduler Middewares)
- 介于 Scrapy 引擎和调度之间的中间件,从 Scrapy 引擎发送到调度的请求和响应
# 2 安装
pip install Scrapy
1
注:windows 平台需要依赖 pywin32
ModuleNotFoundError: No module named 'win32api'
1
pip install pypiwin32
帮助我修改此页面 (opens new window)
上次更新: 2022/11/20, 18:28:09